Share it with your senior IT friends and colleagues
Reading Time: 3minutes
By now, many of us know how to perform RAG (Retrieval Augmented Generation) on a PDF. The RAG pipeline consists of loading the document first and then dividing the large document into smaller chunks.
Embeddings are created of these chunks and stored in a vector database.
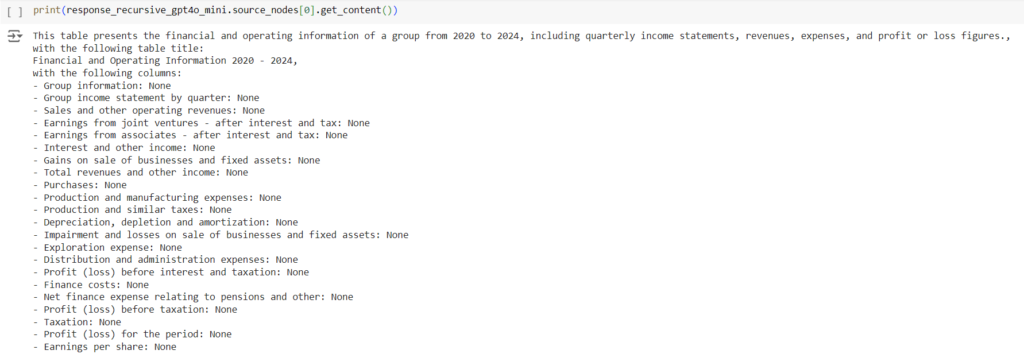
When a user query comes, a semantic search is applied to the database and the relevant chunks are retrieved.
The chunks are sent to the LLM along with the user query for it to generate the answer.
Now the questions are
How can we perform the same operations on an Excel sheet?
How can we load the data?
How can we divide the Excel sheet into smaller chunks?
Namaste and Welcome to Build It Yourself.
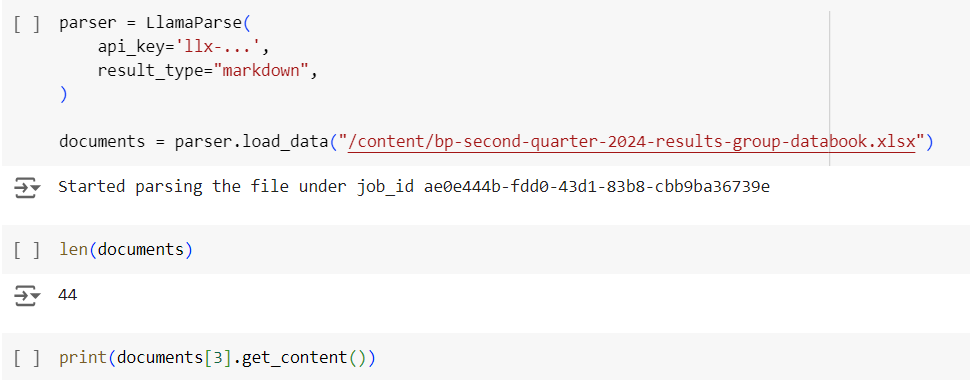
In this tutorial, we will talk about how to perform RAG on an Excel sheet using LlamaParse and GPT4-o-mini
To use it, download and then upload it to your Google Drive and open it as a Google Colab file.
So, how do we do to?
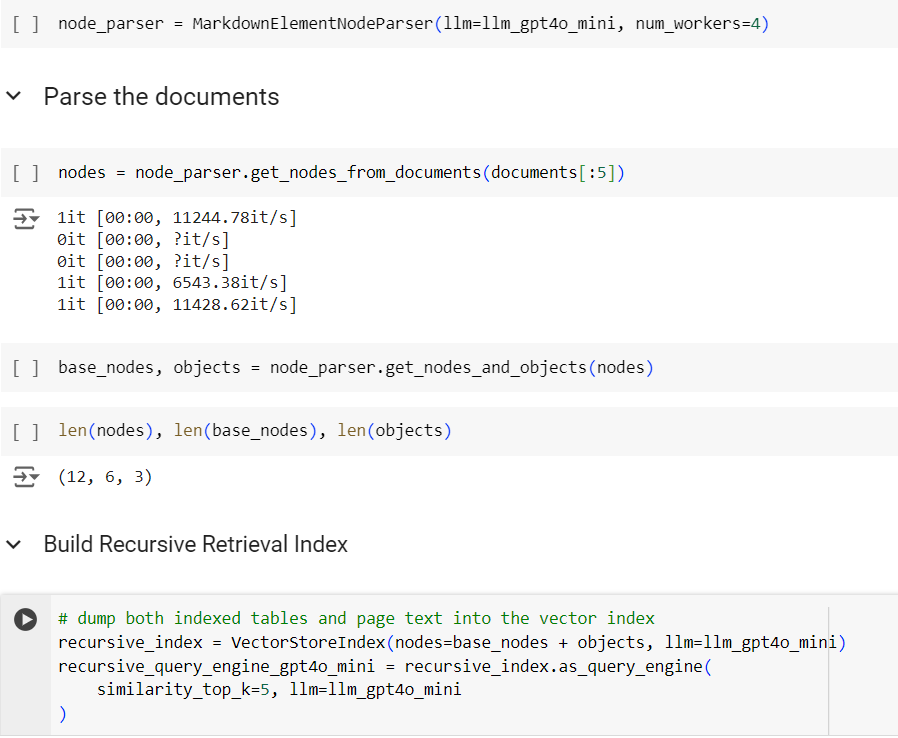
We will use 2 main classes – LlamaParse and MarkdownElementNodeParser.
LlamaParse will parse the excel sheet and load its data
MarkdownElementNodeParser will do the heavy lifting. This class will first divide the data into small nodes and then it will index these nodes for fast retrieval.
Let us see this in detail in code walkthrough below: