Share it with your senior IT friends and colleagues
Reading Time: 7minutes
The initial ChatGPT could only process a single modality which is text, while the latest GPT4-o is a multimodal model.
By Multimodality, we mean Text, Image, Video and Voice.
How did these models start processing multi-modality?
What is the concept behind multimodality?
How is a model trained to process multi-modality?
Can we do RAG using Multimodal models?
What are the possible industry use cases of multimodality?
In this article, we will discuss all these things. So, read on or watch this video.
To understand multimodality, we first need to understand the concept of “Embedding”. The whole magic lies there.
Vector Embedding
Vector embedding is a process of converting words or sentences into numbers in such a way that similar words/ sentences are close to each other.
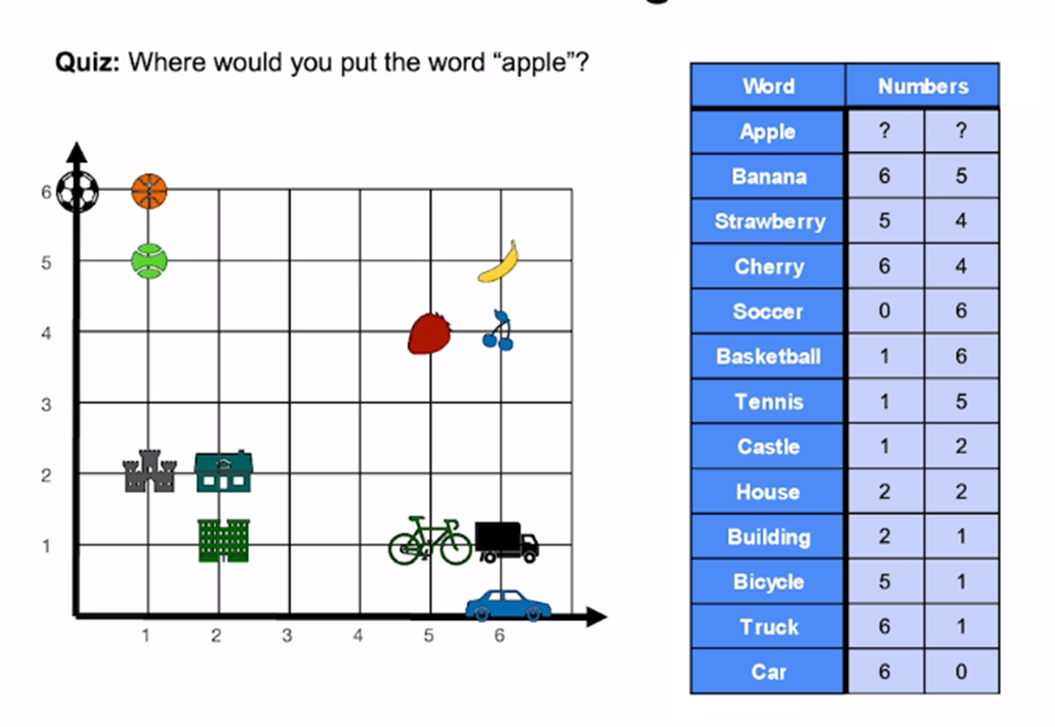
In the below image, words are embedded in a 2-dimensional space.
You could observe that similar kinds of things are close to each other.
For example – Fruits are close to each other, and vehicles like car, truck, cycle are also close to each other.
The same is the case with the type of buildings and balls.
This 2-dimensional space is for easy demonstrational purpose. However, words/ sentences are embedded in a 1000-dimensional space.
What this means is that a sentence will be provided a point in a 1000-dimensional space and its embedding is nothing but the coordinates in that space.
Now, if 2 sentences have the same meaning, they will be closer to each other while if they have different meanings, they will be farther apart and vice versa.
The distance is calculated by using various methods and Cosine distance is one of the prominent ones.
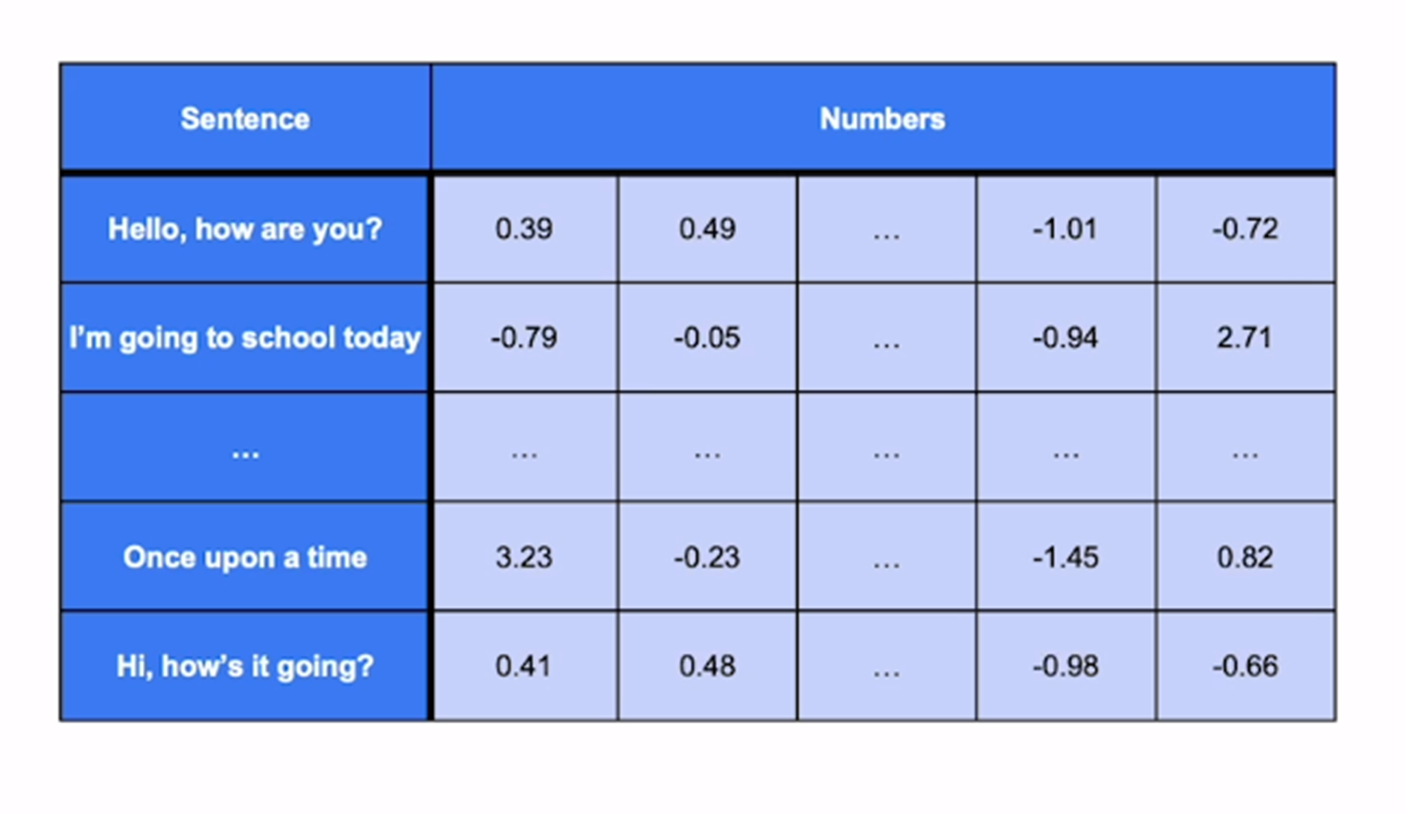
In the above example, 2 below sentences have almost the same meaning
– Hello, how are you?
– Hi, how’s it going?
And we can see the embedding is also almost the same.
Also, you can see the embedding is very different from the other 2 sentences as they are not similar in meaning.
So, in a nutshell, embedding helps models understand the similarity between words and sentences.
Multi-lingual Embeddings
As we understood Embedding, answer this question – Should the same sentences in different languages have the same vector embeddings?
Well, if you have understood the embedding concept well, your answer would be – Yes. The same sentences in different languages should have the almost same vector embedding.
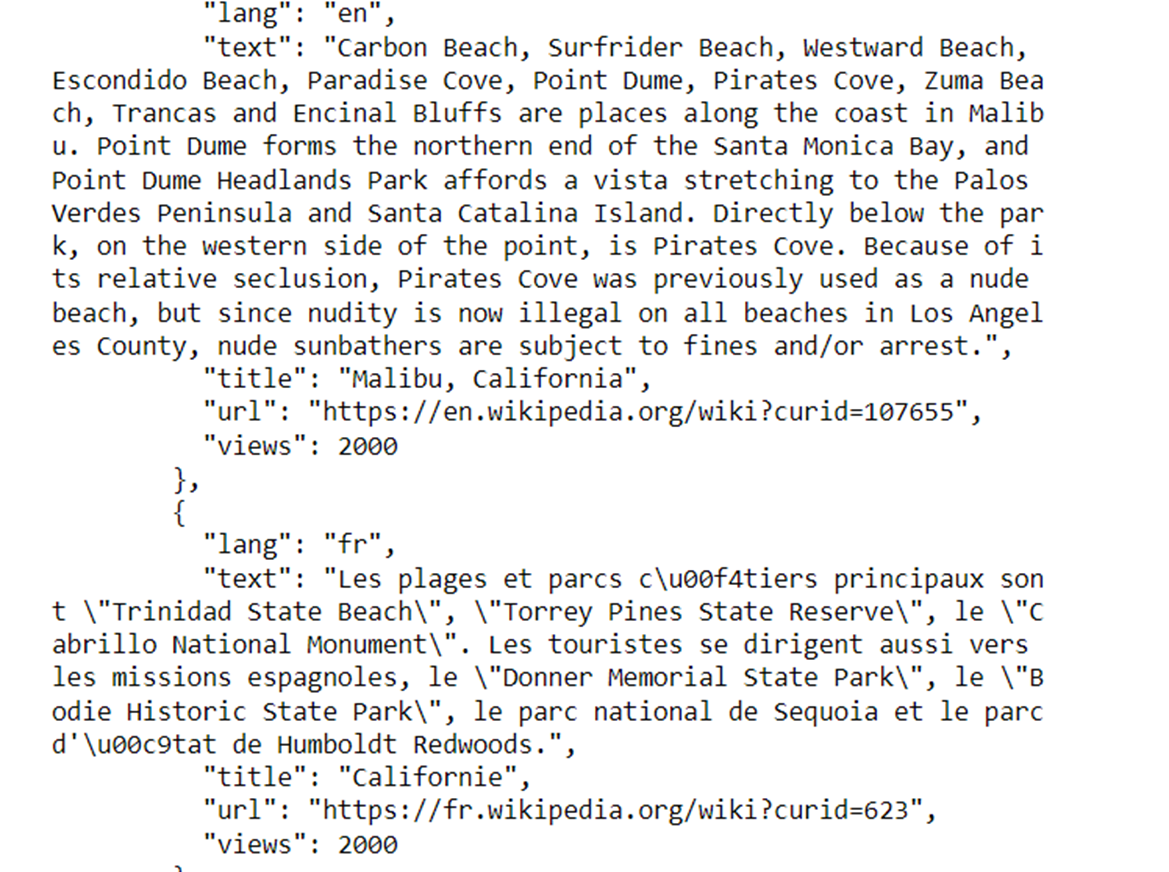
You can see this in the above example. “Vacation spots in California” and the same sentence in Chinese have almost the same embedding.
So, with this, models could do language translation. In the below code, we will ask the question – “Vacation spots in California” in English but can get an answer in any language we specify.
In the below example, we specified “French” and got the answer,
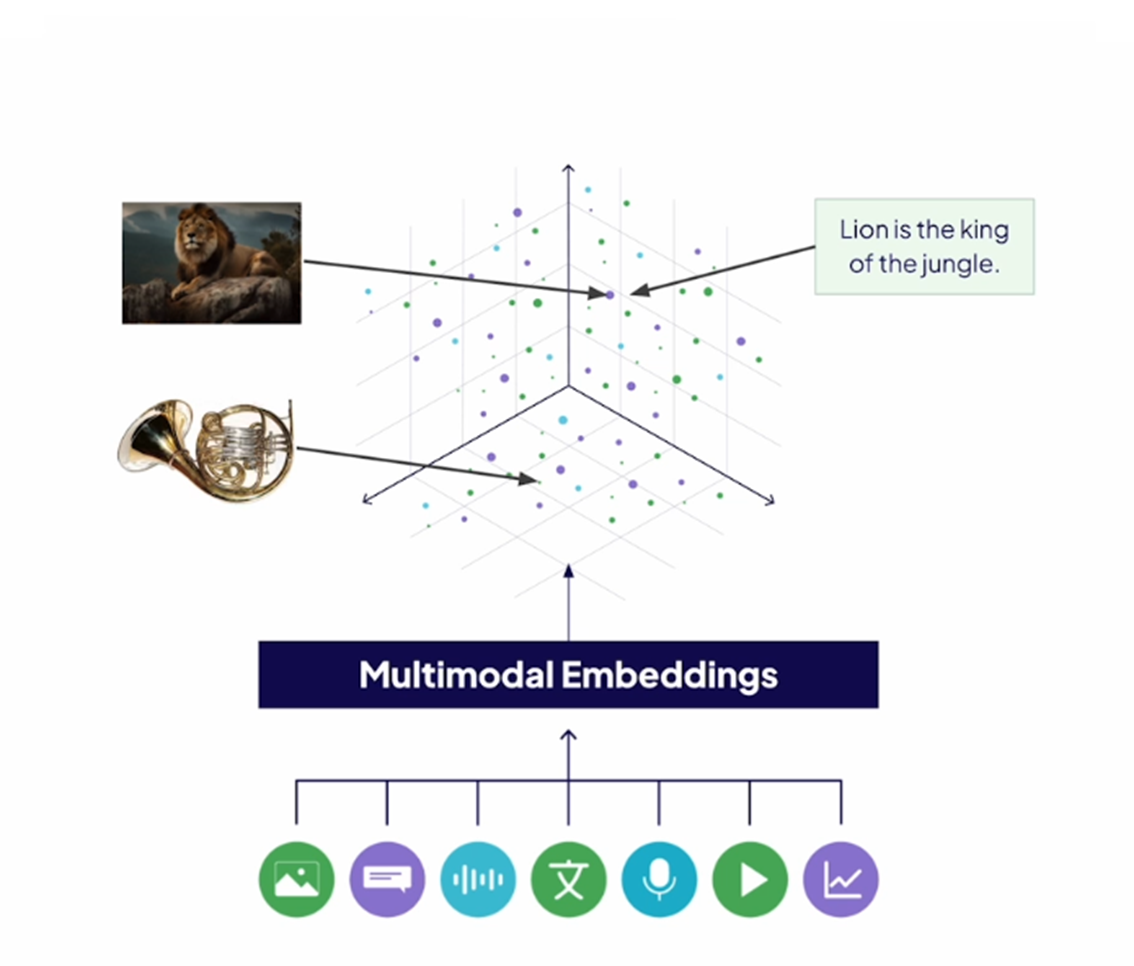
Multi-modality Embeddings
Multi-modality follows the same concept – The same vector embeddings for different modalities
For example – consider we have below 4 entities:
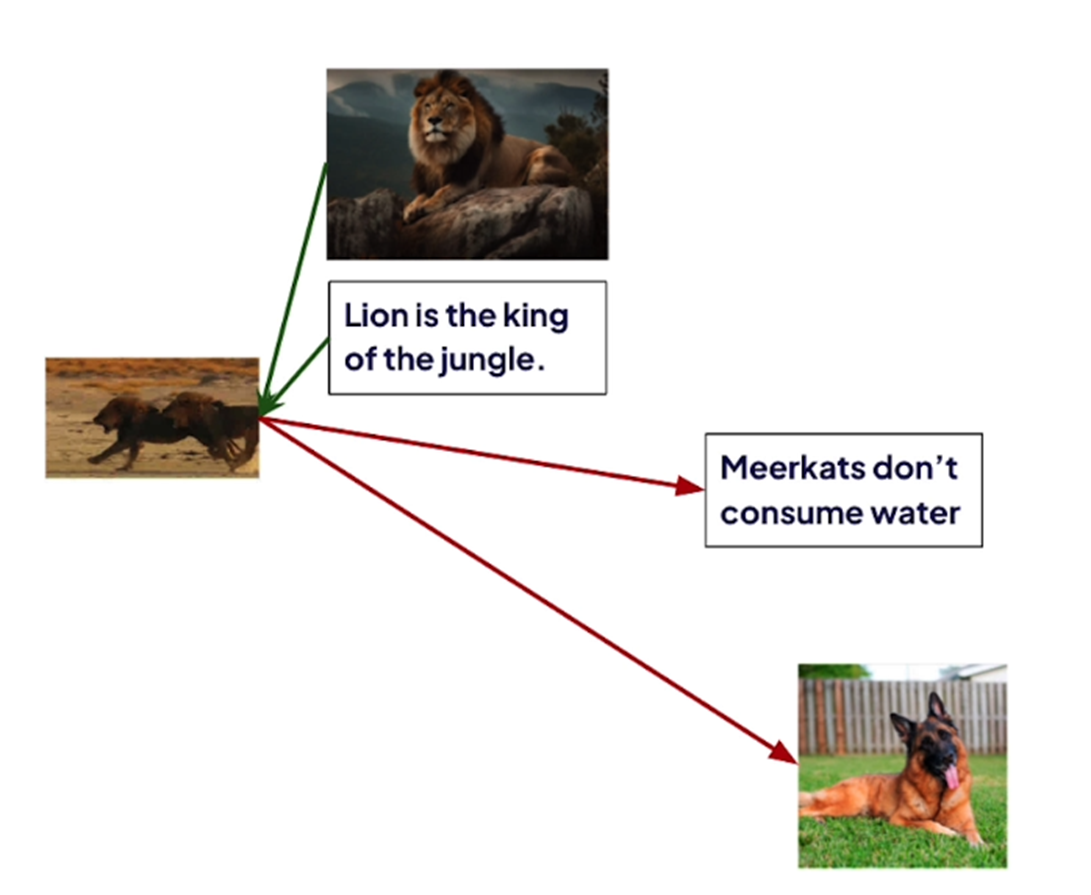
Text – The lion is the king of the jungle
Image of a Lion
Voice – The lion is the king of the jungle
Video of a lion running in a jungle
There are 4 different modalities but if we create embedding for them in the same vector space, they should be almost the same.
With this Multi-modality embedding concept, the models become Multimodal LLMs.
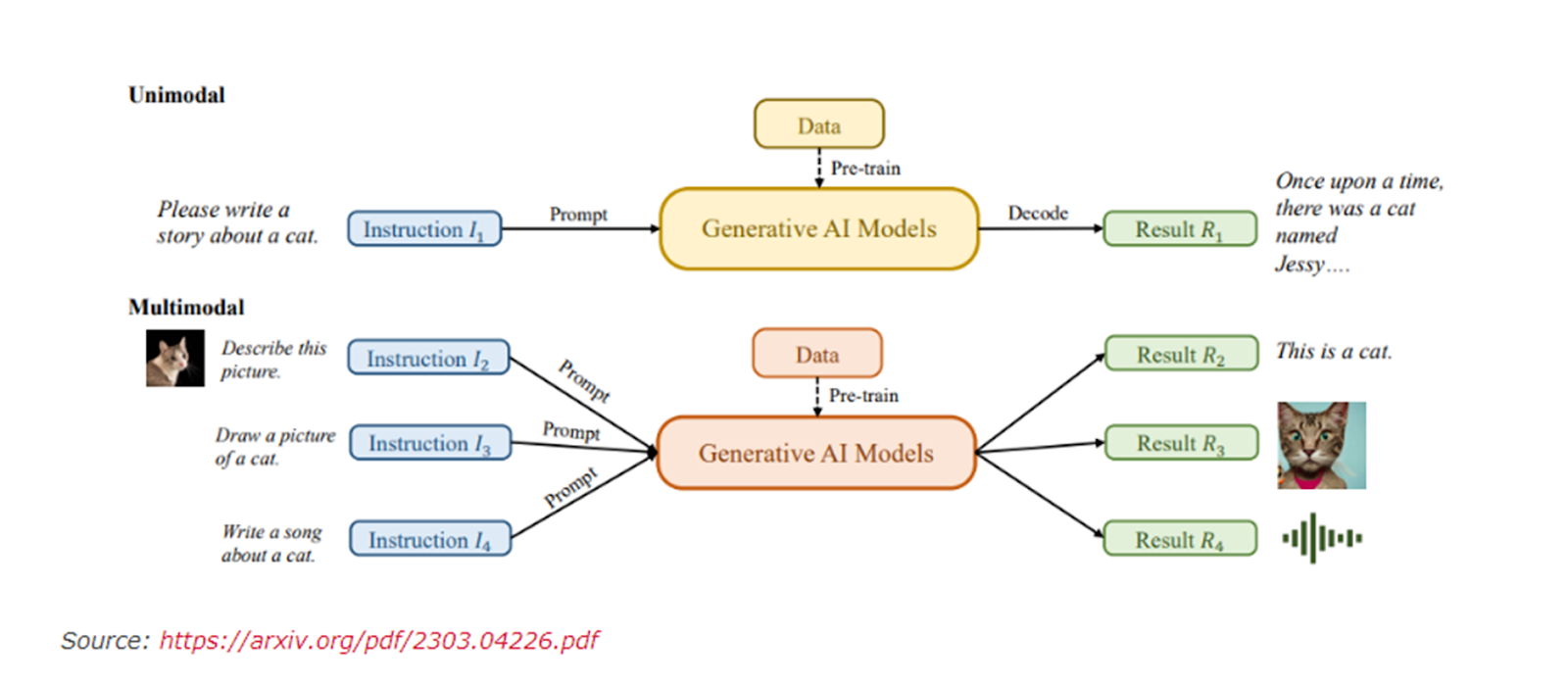
In the figure above, we can see earlier Large language models were Unimodal. They take text as an input and provide text as an output.
However, now they have become “Multimodal LLMs” or “Large Multimodal models”. They can now take a variety of modalities as inputs and can generate output also in multiple modalities.
How to generate Multimodal Embeddings
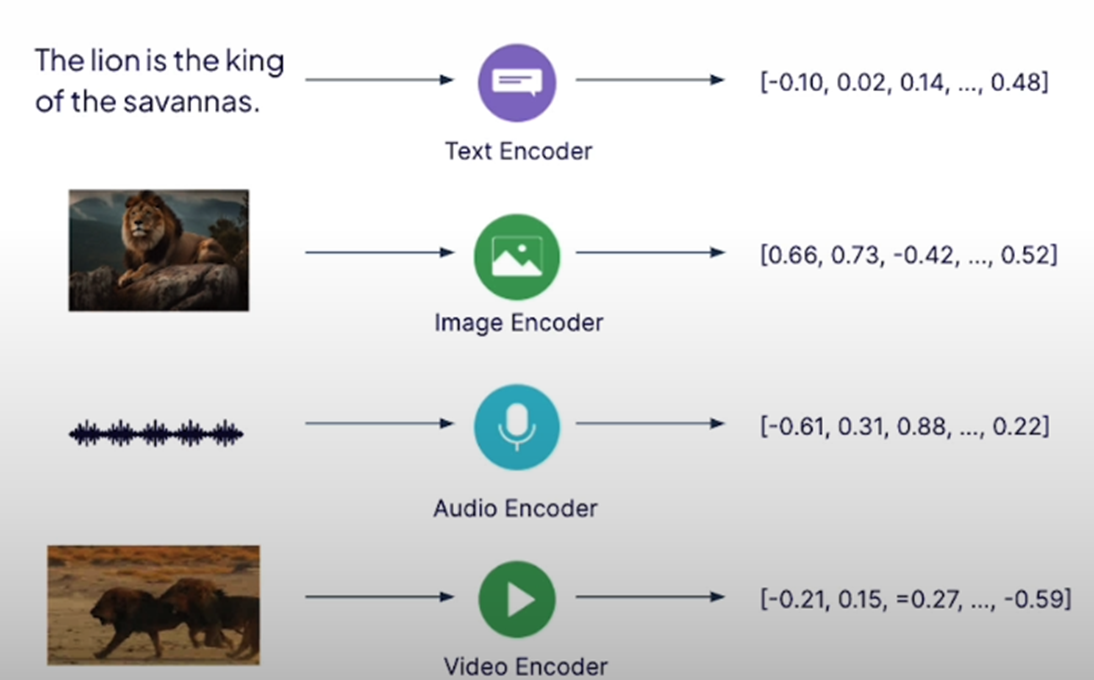
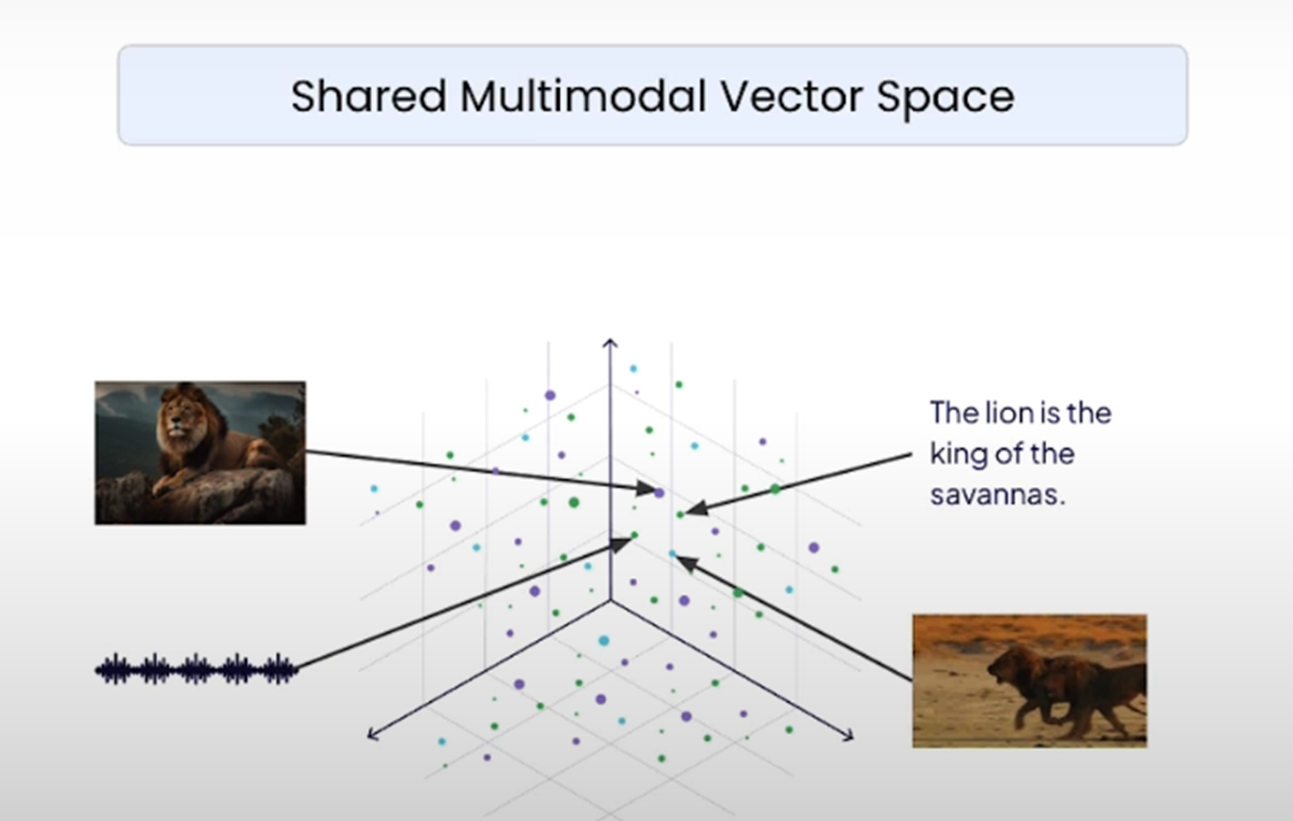
As we know magic lies in embedding. In the above image, you can see embeddings of the text – Lion is the king of the jungle and an image where a lion is sitting on a rock in a jungle are almost the same.
So, how multimodal embeddings are being created?
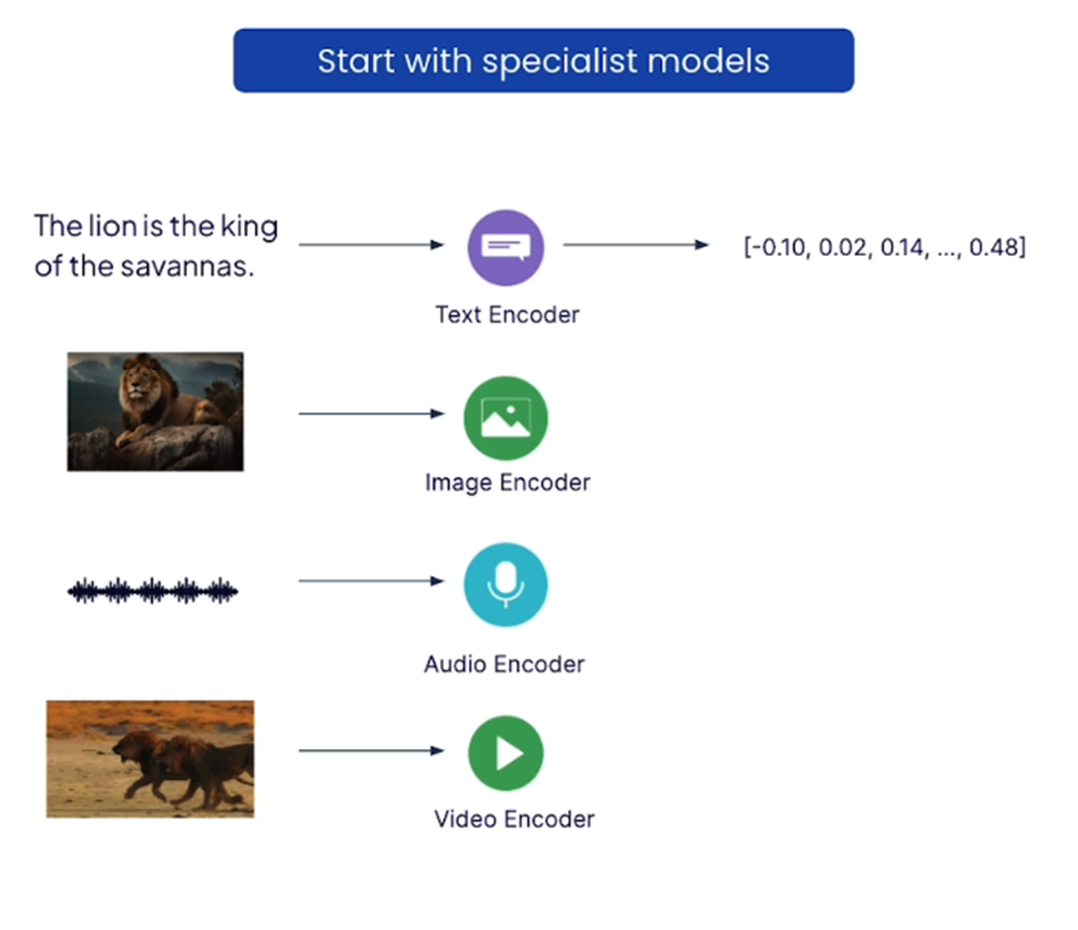
Step 1 – Start with creating separate embedding of each modality using the specialist encoders.
Step 2 – Unify these embeddings in the same vector space using a method called Contrastive representational learning
Contrastive representational learning
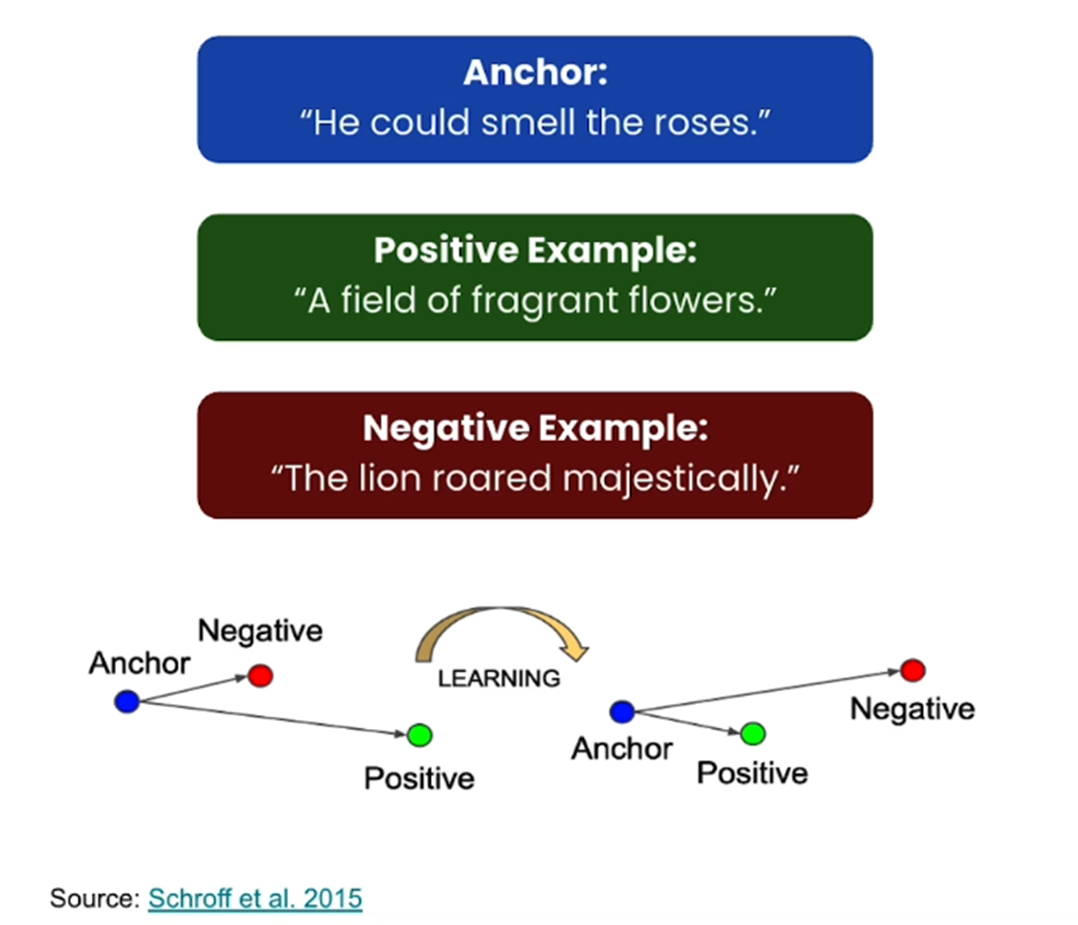
Let us first understand Contrastive representational learning for Text.
The idea is pretty simple.
We first have our anchor text,
One positive example – the meaning is similar to the anchor text
One negative example – the meaning is completely different from the anchor text.
For clarity, check the 3 sentences in the above image.
Now the model should learn that the positive example is similar to the anchor text and the embedding should be close and at the same time it should learn that the negative example should be farther from the anchor.
The model learns by minimising the “contrastive loss function”.
So, by using the contrastive loss function, the positive example comes closer to the anchor text while the negative example goes farther.
Multi-modal Contrastive representational learning
The same Contrastive representational learning concept is applied to multimodal data
In multimodal contrastive representational learning, all the 3 – anchor, positive and negative examples could be of different modalities.
However, the concept is the same, by calculating the contrastive loss function, the positive example comes closer to the anchor while the negative example goes farther.
And we get embeddings for multi-modal data in a single multi-dimensional vector space.
Now, this brings us to the concept of Large Multimodal Models.
What are Large Multimodal Models?
To understand LMMs, let us recall what Large Language Models are:
Most LLMs are pre-trained transformers
They generate text one token at a time
Unsupervised training using next-token prediction
Generate tokens based on probability distribution
Like Text transformers, there are now Vision Transformers
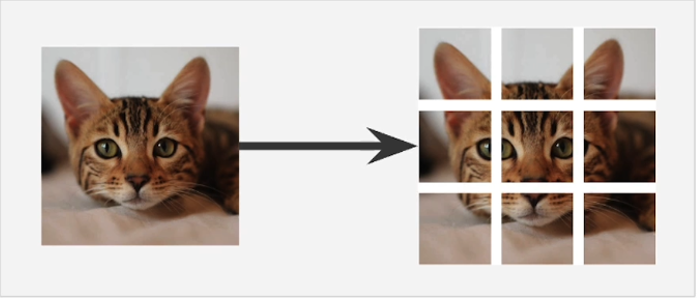
What are Vision Transformers?
In Vision Transformers, an image is cut into patches
And each patch is embedded. Like the Text transformer predicts the next or missing word, the Vision transformer predicts the next or missing patch.
So, the vision transformer outputs a probability distribution over the possible classes.
RAG with LMMs
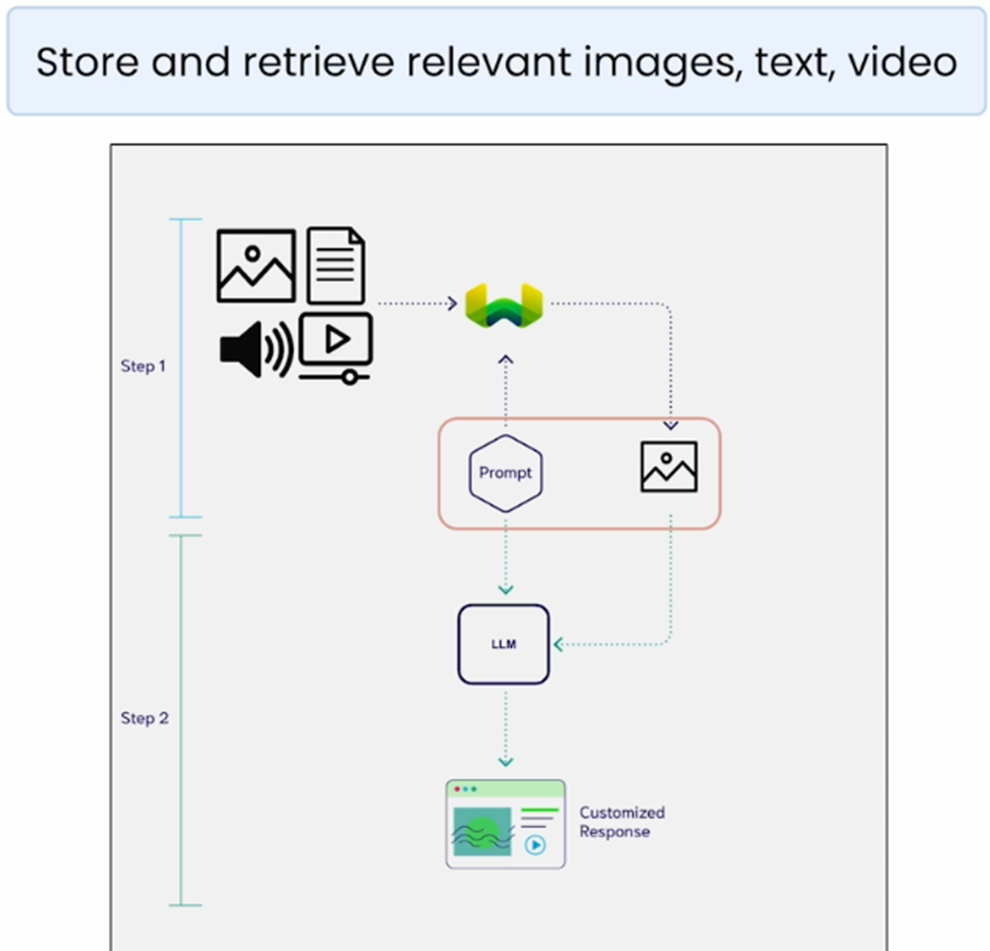
With Multimodal embeddings, RAG can also be done on multi-modal data.
We can now create multimodal embeddings, store them in a vector database, and do Retrieval Augmented Generation on multimodal data.
Now Organizations are not just restricted to RAG for text data like PDF, they can now add all their data irrespective of the modality and build a RAG pipeline on top of it.
What are the practical applications of LLMs
Well, by now we already know what multimodal models can do. When OpenAI launched GPT4-o, they demonstrated several use cases. Check out their Youtube channel if you haven’t watch those videos
Some of the other real-life applications could be:
Structured Data Generation
LMMs can be used to extract information from an image. In the above example, a hardcopy of an invoice was converted into JSON format
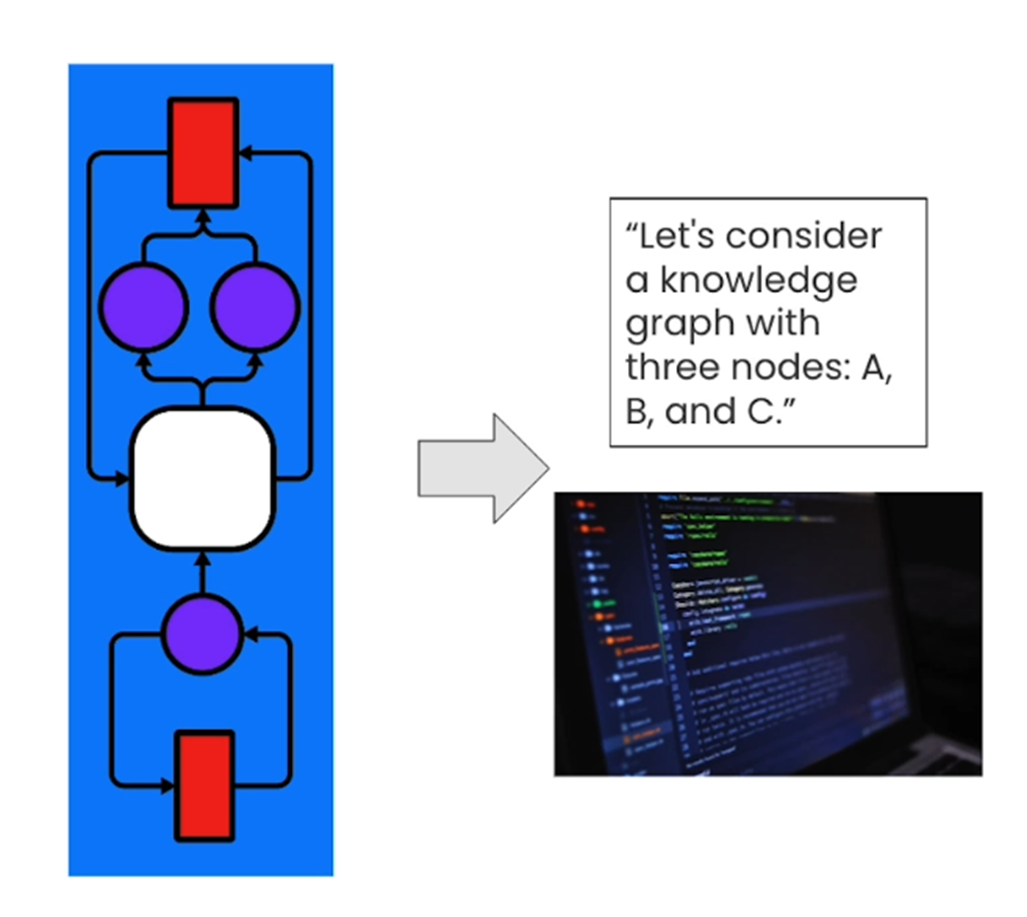
Understanding Logical Flowcharts
With the help of LMMs, one can identify the algorithm for a flowchart and convert it into any programming language of your choice. One can also ask LLM to explain the logic in simple language.
Image Description
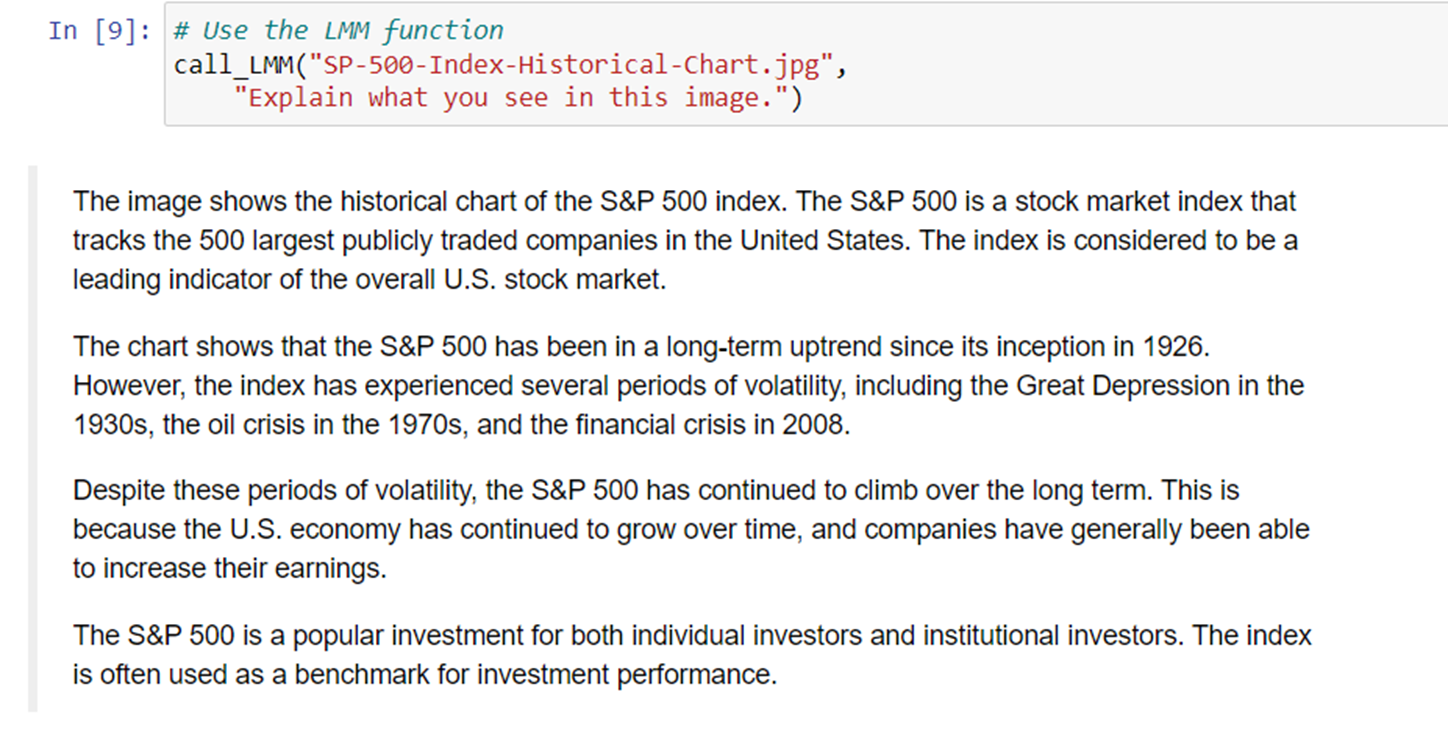
We already know that LMMs can describe images or your surroundings in real-time. Another use case is asking LLMs to explain complex graphs or pictures.
Conclusion
The ultimate goal of AI research is to attain AGI and AGI can not be achieved without multimodality.
With time, AI models will gain more multi-modality capabilities. Hope these capabilities are used to improve human life.
Tailored AI + LLM Coaching for Senior IT Professionals
In case you are looking to learn AI + Gen AI in an instructor-led live class environment, check out these dedicated courses for senior IT professionals here
Disclaimer – The images are taken from Deep Learning AI’s course We are just using it for educational purposes. No copyright infringement is intended. In case any part of content belongs to you or someone you know, please contact us and we will give you credit or remove your content.
Post Views:1,215
Share it with your senior IT friends and colleagues