Share it with your senior IT friends and colleagues
Reading Time: 6minutes
Much research has been going on in RAG for the past couple of years.
While it started with a simple semantic search for retrieval, now multiple advanced retrieval techniques have emerged.
What is the limitation of the simple semantic search retrieval technique, you ask?
Well, sometimes simple vector search can also retrieve distractors (entries that are not relevant)
And hence we need retrieval techniques better than just a simple semantic search.
In this article, we will talk about these advanced retrieval techniques that have come up recently.
9 Advanced Retrieval Techniques you must know
1. Query Expansion
In this technique, the original query is converted into multiple similar queries. Retrieval is then done using all these queries instead of a single query.
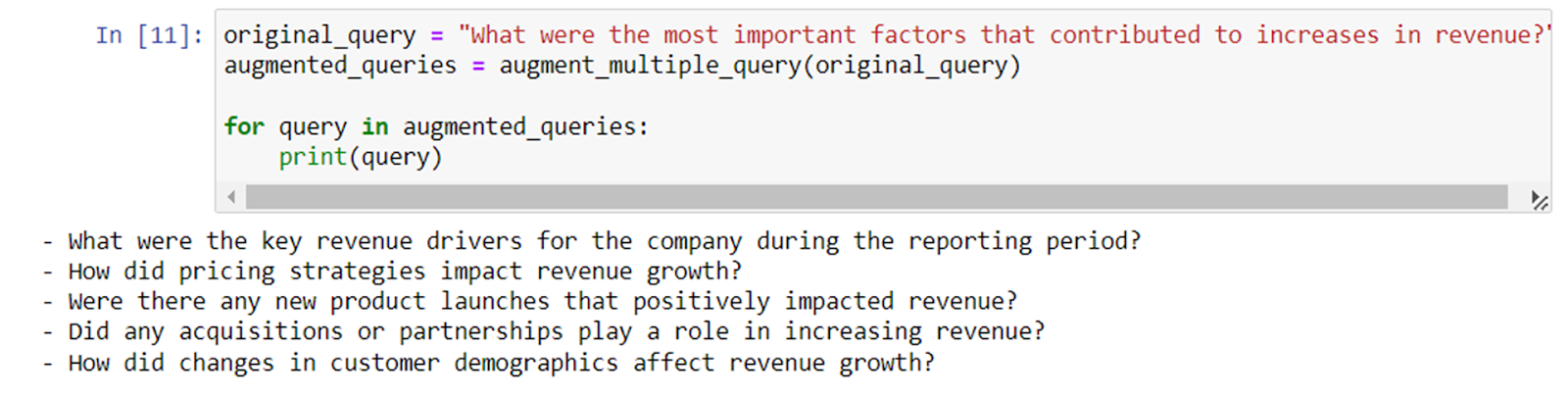
For example – the original query was “What were the most important factors that contributed to increases in revenue?”
We passed the original query to the “augment_multiple_query” function and we got 5 new queries
What were the key revenue drivers for the company during the reporting period?
How did pricing strategies impact revenue growth?
Were there any new product launches that positively impacted revenue?
Did any acquisitions or partnerships play a role in increasing revenue?
How did changes in customer demographics affect revenue growth?
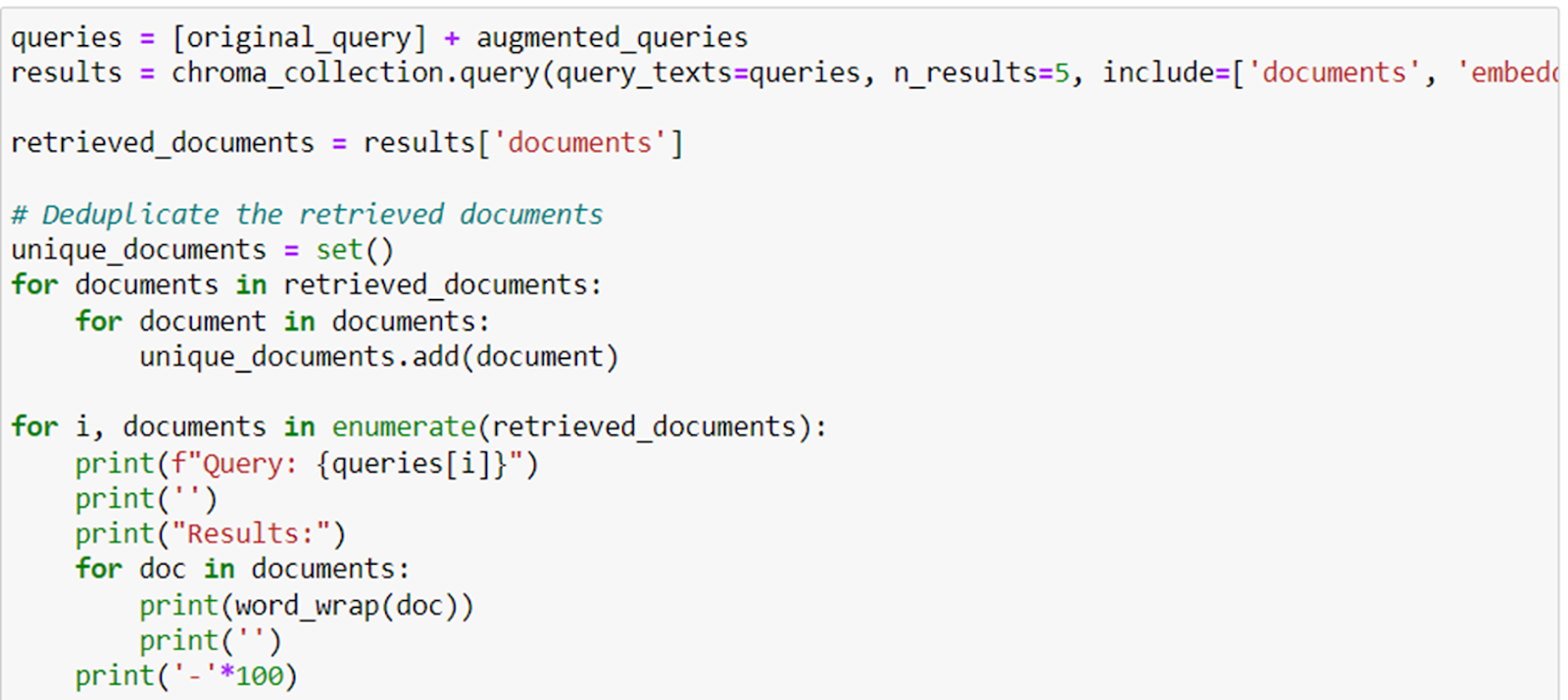
The original query is expanded with these augmented queries and then retrieval is done.
The idea is to reframe the question and get all possible retrieval chunks so that the LLM gets all possible context to generate the answer.
2. Cross Encoder Re-Ranking.
I am sure you must have identified a drawback in the previous approach. If not, please spend a moment to identify a problem with the above technique.
Yes, we are passing on too much information (or too many input tokens). This would not only increase the price but also might send irrelevant information to the LLM.
So, what is the solution?
A simple solution that comes to mind is – instead of sending all the retrieved information, can we rank the chunks based on certain criteria and send only the top-ranked chunks?
But how do we rank the chunks?
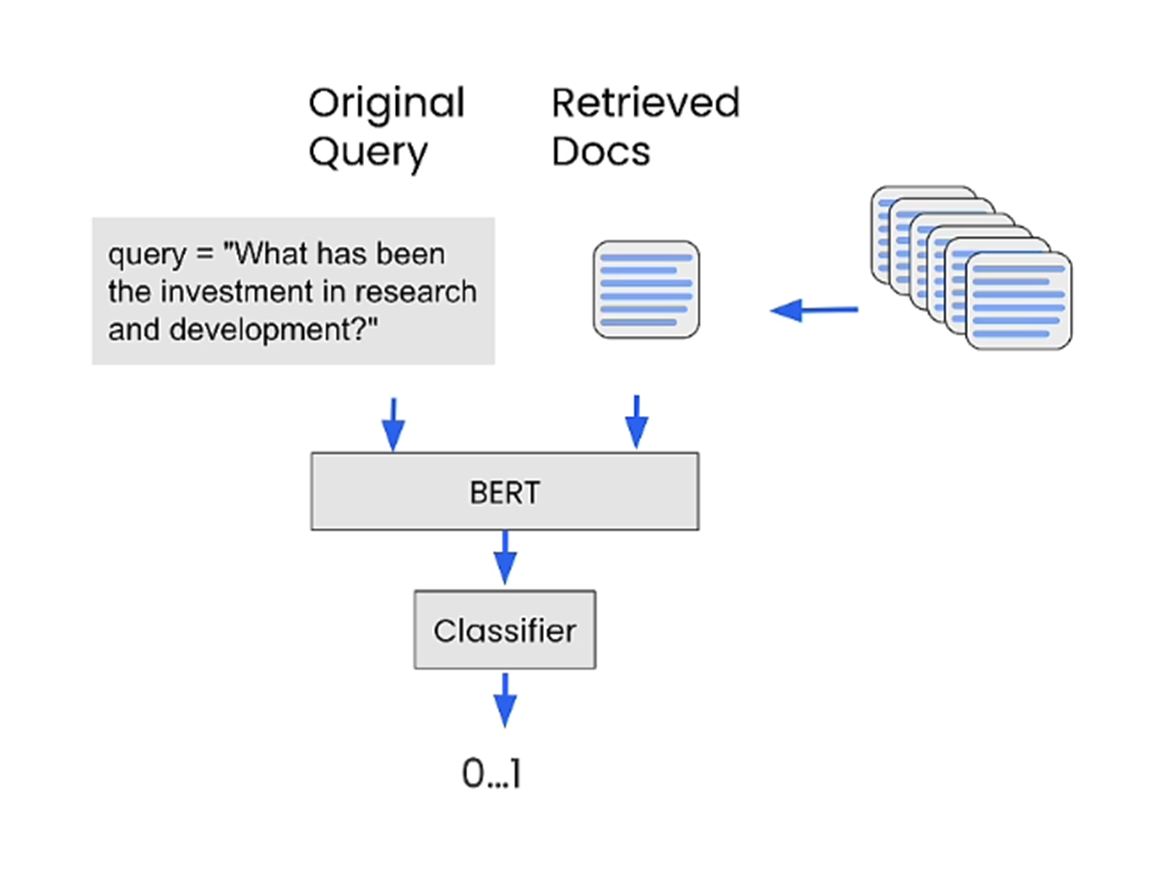
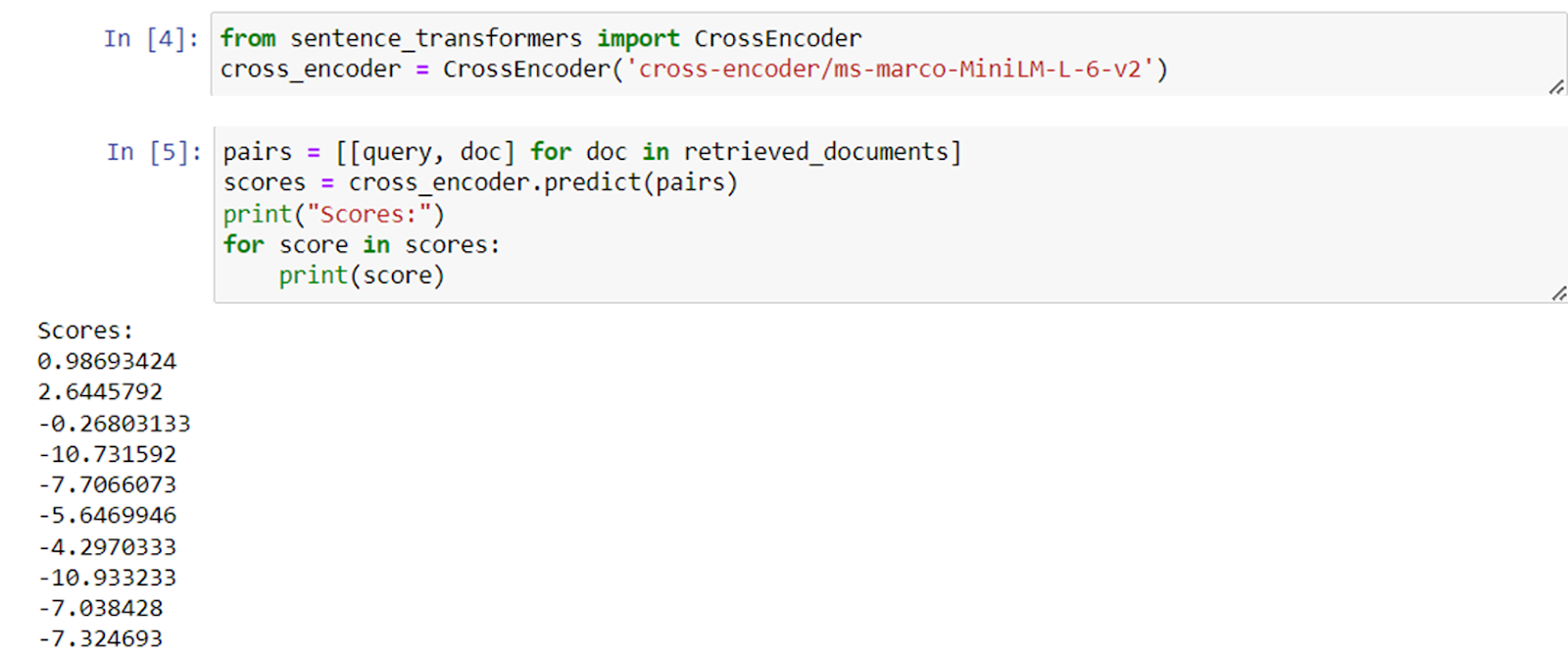
Well, the answer is using Cross Encoder.
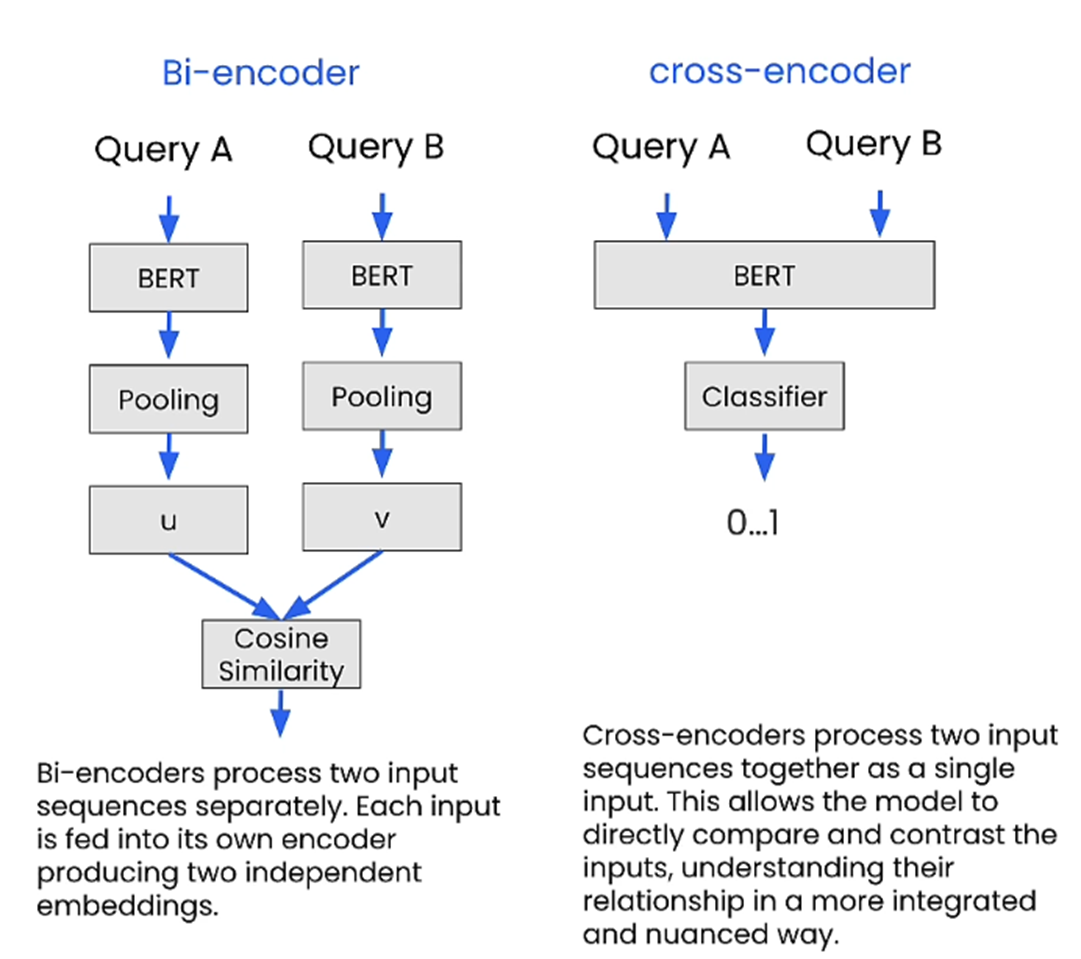
So, what is a Cross Encoder?
Cross Encoder is a technique in which 2 input sequences are processed together as a single technique. This allows the model to understand the relationship between the two sequences and the model provides a similarity score.
This is the same like classification with a higher score meaning similar and a lower score meaning not similar.
With these scores, we can rerank the retrieved chunks
Once reranked, we can choose not to send all retrieved chunks and send only a few chunks with higher points.
This technique seems to be more common sense than advanced. What do you think?
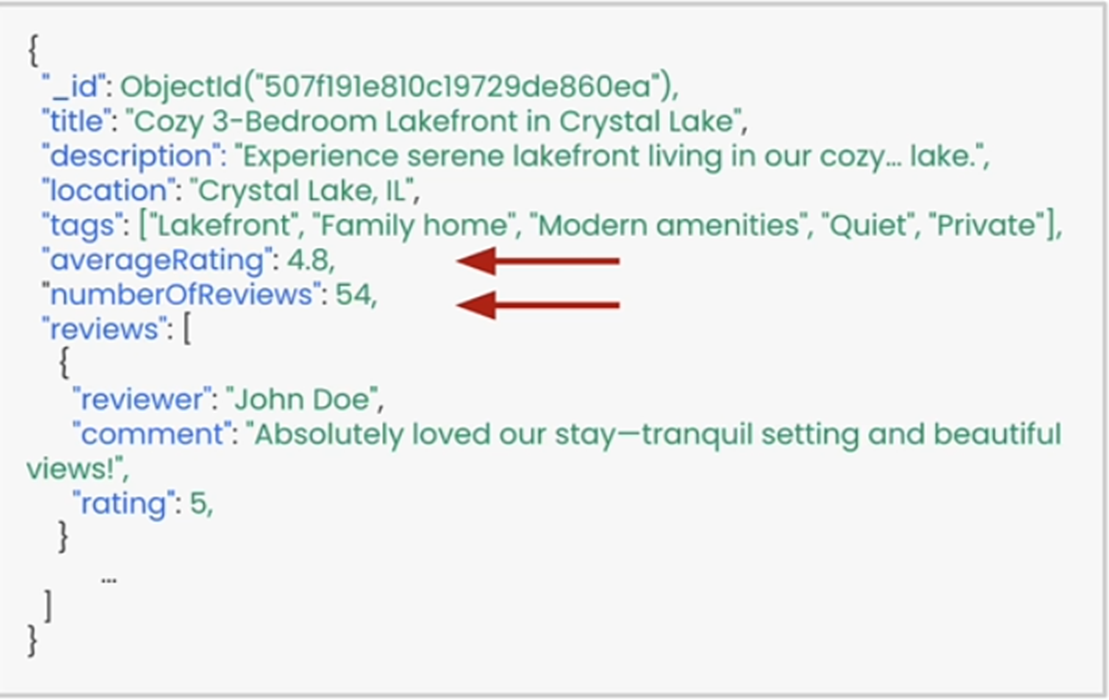
3. Filtering with Metadata
Metadata as we know is supplementary information that describes the primary data.
Metadata is required to add context, enhance relevance, enable filtering & sorting, etc.
What if we filter the data based on Metadata to get more relevant information?
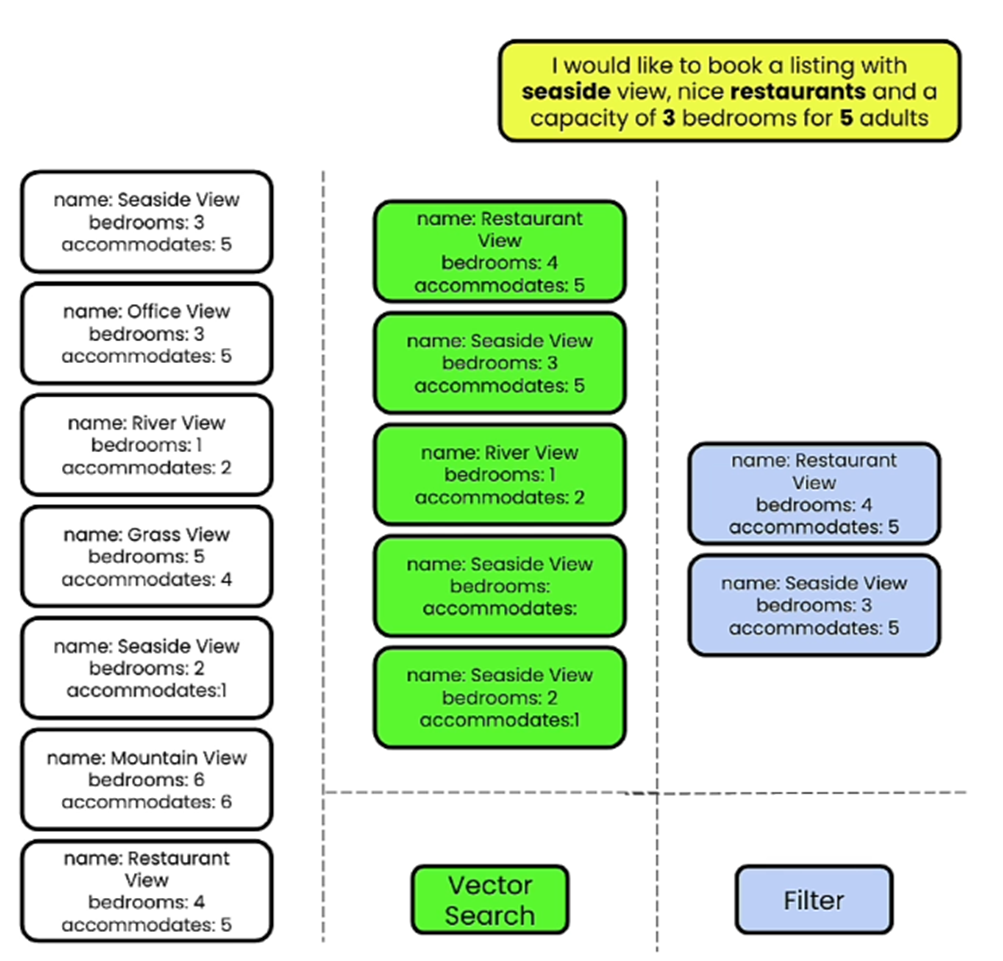
For example – We have a query – “I would like to book a listing with a seaside view, nice restaurants and a capacity of 3 bedrooms for 5 adults.
We can now retrieve the results using semantic search and then filter based on the Metadata
4. Projection
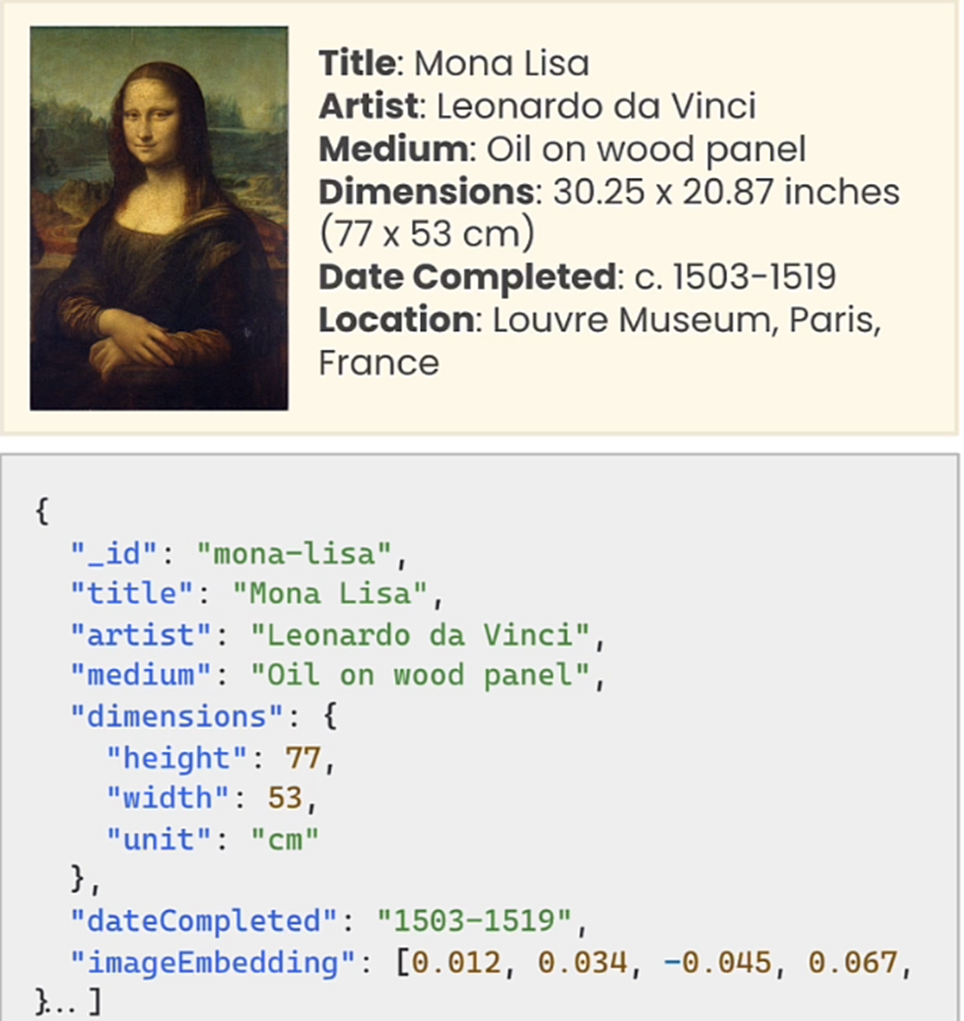
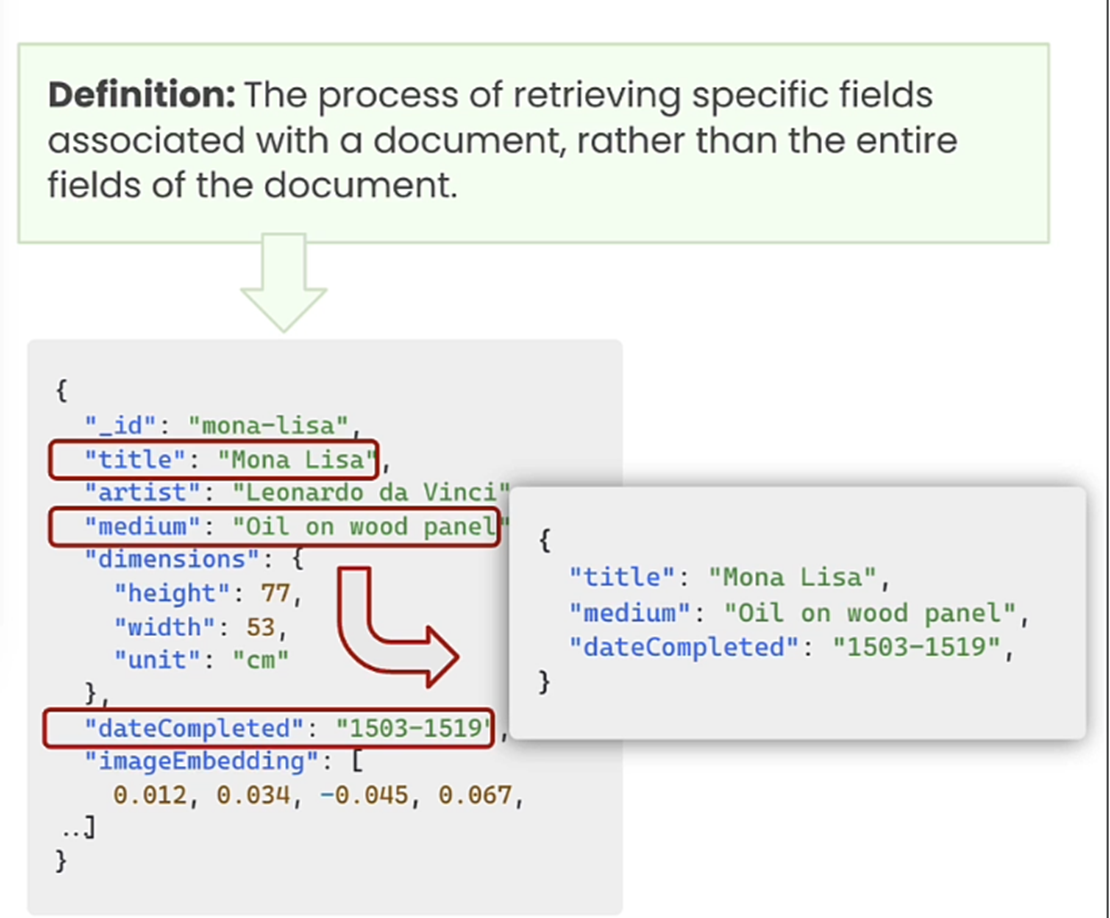
In this advanced retrieval technique, we try to reduce the number of fields.
Basically, it’s a process of retrieving specific fields associated with a document, rather than the entire fields of the document.
So, how does it help?
It reduces the amount of data to be transferred and memory usage on the client side. It also optimizes the query speed.
This technique is more for improving the performance of the RAG system rather than improving the generated output.
5. Boosting
In Boosting, reranking is done based on Metadata. So, we save on using Cross Encoder to rerank the retrieved results.
The benefits are the same as ReRanking using Cross Encoder. The technique improves relevance, retrieval credibility and personalize results.
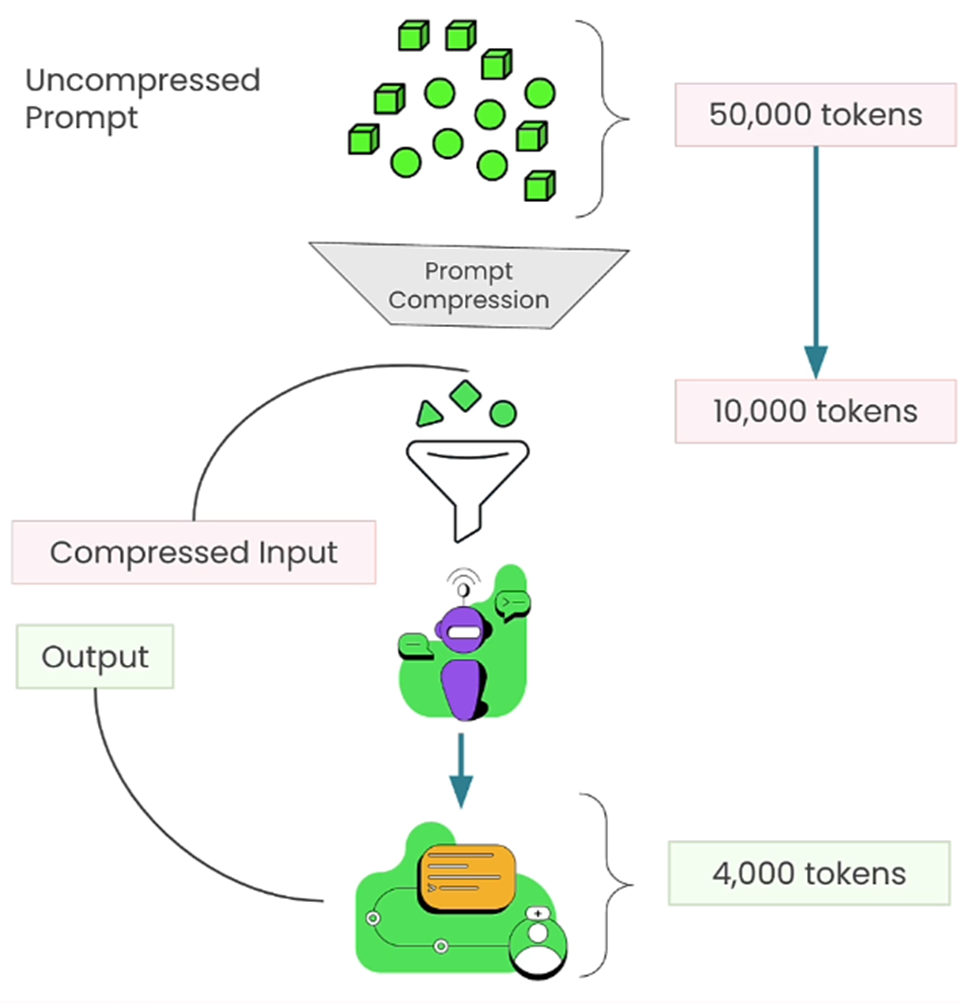
6. Prompt Compression
One major problem in any RAG system is to provide more context to the LLM. However, more context means more input tokens and hence more expense.
Can we provide more (or enough) context by reducing the size of input chunks?
By using the Prompt compression technique, we can do exactly the same.
As you can see in the above example, the original text was compressed to reduce the number of prompt tokens.
Basically, prompt compression is a technique to systematically reduce the number of tokens fed into an LLM.
The idea is to retain the output quality comparable to that of the original, uncompressed prompt.
7. Sentence Window Retrieval
In this advanced retrieval technique, chunks are created for every sentence and not for a group of sentences.
With sentence-level chunks, we retrieve the most relevant sentence + surrounding sentences and pass it on to LLM.
This technique enhances specificity as the segments retrieved are more relevant to the query. Moreover, the surrounding context enriches the generation process.
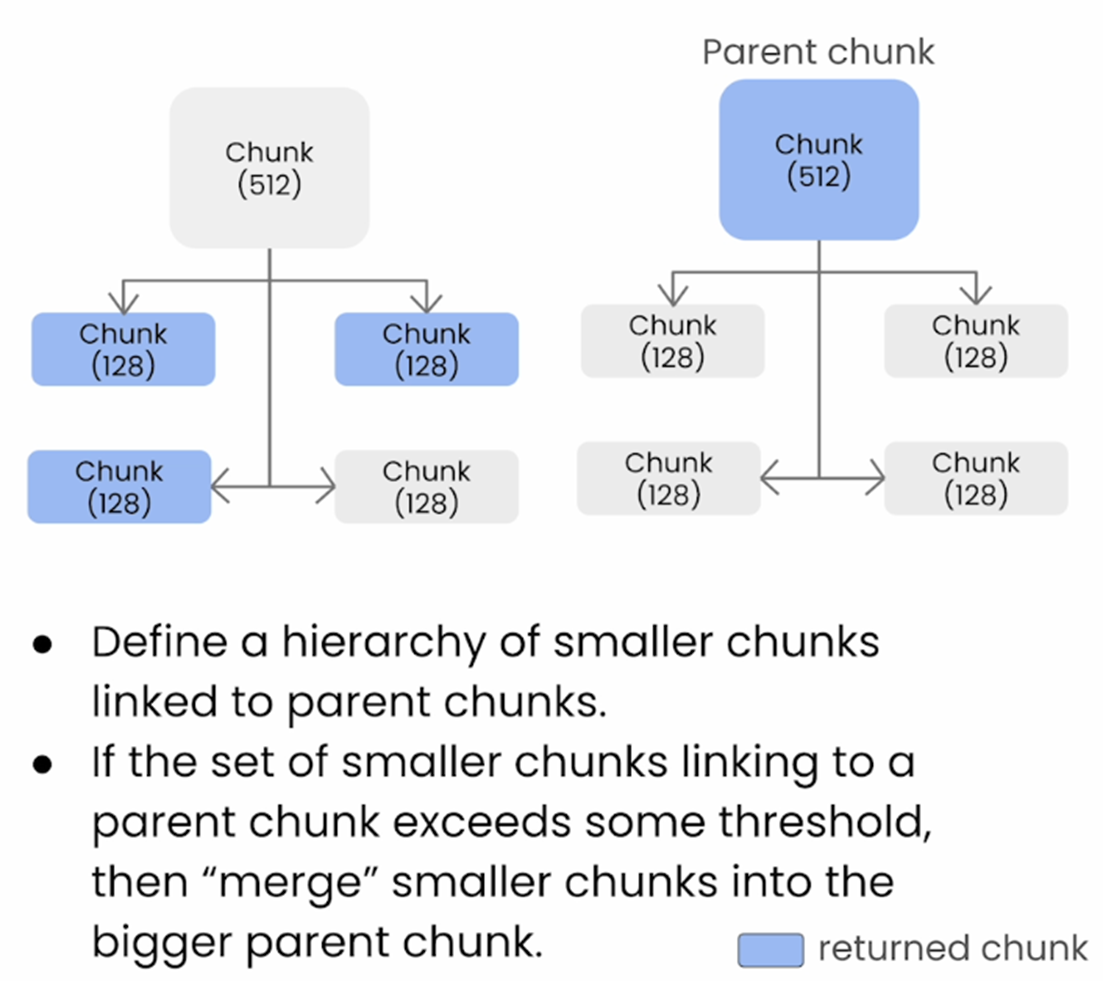
8. Auto-merging Retrieval
This is another useful advanced retrieval technique which has come into prominence lately.
In this technique, a bigger chunk is divided into smaller chunks. The bigger chunk is then mapped to smaller chunks hierarchically.
While retrieving, the smaller chunks are retrieved, but if smaller chunks linked to a bigger chunk exceed a certain threshold then the whole parent (bigger) chunk is retrieved.
Auto-merging retrieval technique works best in most of the evaluation parameters like Groundedness, answer relevance and context relevance.
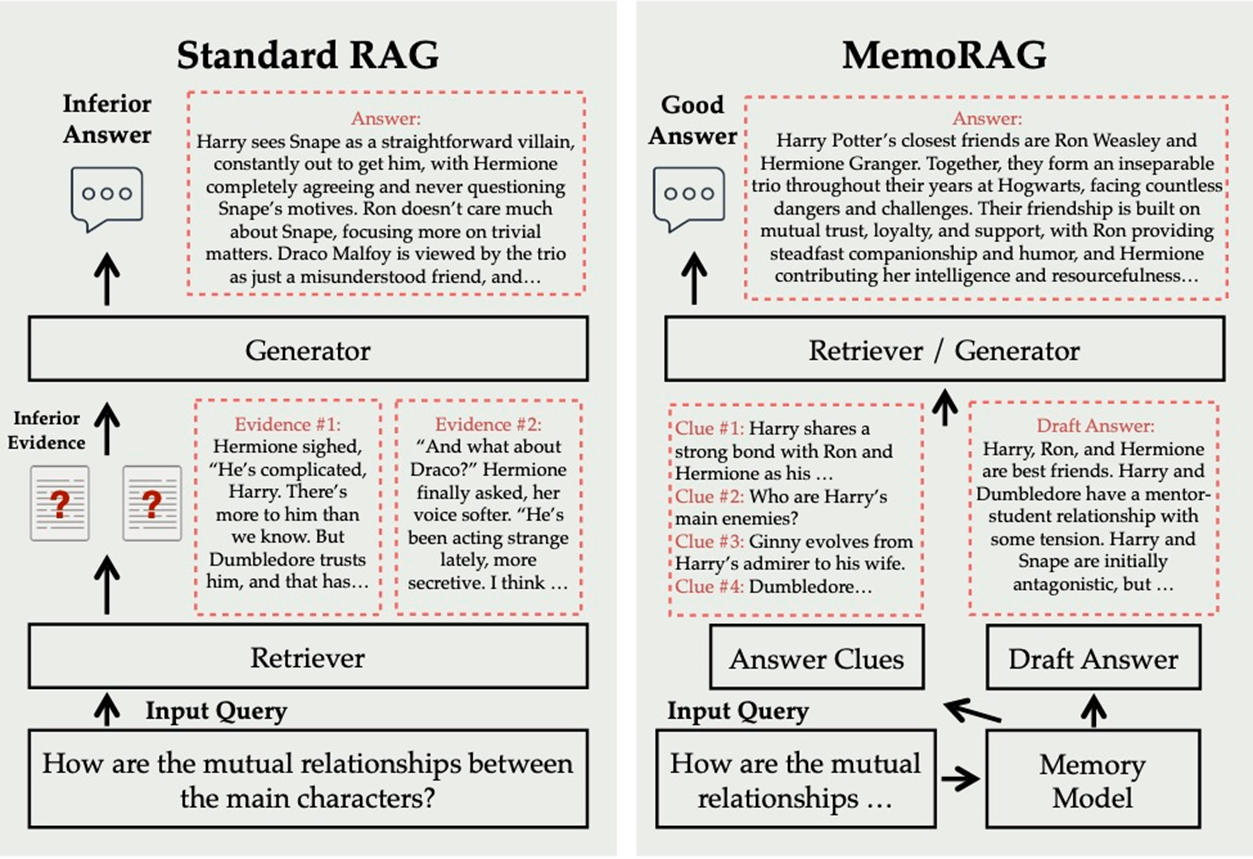
9. MemoRAG
MemoRAG is an advanced retrieval technique that came recently only.
While Traditional RAG depends on the “Retrieved chunks” from the vector database to generate the answer
MemoRAG leverages its memory model to understand the entire database globally.
By recalling query-specific clues from memory, MemoRAG enhances evidence retrieval, resulting in more accurate and contextually rich response generation.
Conclusion
Over the past couple of years or so, the release of new Large Langauge Models and their increasing application across various fields has also spurred a surge in research on Retrieval Augmented Generation approaches.
And this is not going to slow down. New research will keep on going and more & new advanced retrieval techniques will emerge.
Which technique will be most effective for businesses is what we need to watch out for.
Please feel free to share any advanced retrieval technique you are aware of with us and we will add to the article by giving you proper credit.
The most up-to-date AI + LLM Coaching
In case you are looking to learn AI + Gen AI in an instructor-led live class environment, check out these courses
Disclaimer – The images are taken from Deep Learning AI’s course We are just using it for educational purposes. No copyright infringement is intended. In case any part of content belongs to you or someone you know, please contact us and we will give you credit or remove your content.
Post Views:669
Share it with your senior IT friends and colleagues